Linux三剑客之grep
本文共 7102 字,大约阅读时间需要 23 分钟。
一、概述
grep(global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
这也是一个我们比较常用的命令之一,好多时候虽然没通过系统的学习,但是我们还是会经常用到。通过帮助文档我们可以得知,egrep、fgrep是grep的别名。网上一些文章说egrep、fgrep与grep有区别,这种说法是不准确的。让我们来用实际例子来看一下:[grep@GeekDevOps ~]$ alias | grep grepalias egrep='egrep --color=auto'alias fgrep='fgrep --color=auto'alias grep='grep --color=auto'
再通过man看一下:
[grep@GeekDevOps ~]$ man grepGeneral Commands Manual GREP(1)NAME grep, egrep, fgrep - print lines matching a patternSYNOPSIS grep [OPTIONS] PATTERN [FILE...] grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]
但是,pgrep跟grep就有点区别了,大家可别搞混淆啦!接下来的内容就只扯grep这个梗!
二、使用介绍
1.命令格式(用法)
grep [OPTIONS] PATTERN [FILE...]grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]
在每个 FILE 或是标准输入中查找 PATTERN。
默认的 PATTERN 是一个基本正则表达式(缩写为 BRE)。 例如: grep -i ‘hello world’ menu.h main.c 2.选项(也就是上面提到的:OPTIONS)正则表达式选择与解释: -E, --extended-regexp PATTERN 是一个可扩展的正则表达式(缩写为 ERE) -F, --fixed-strings PATTERN 是一组由断行符分隔的定长字符串。 -G, --basic-regexp PATTERN 是一个基本正则表达式(缩写为 BRE) -P, --perl-regexp PATTERN 是一个 Perl 正则表达式 -e, --regexp=PATTERN 用 PATTERN 来进行匹配操作 -f, --file=FILE 从 FILE 中取得 PATTERN -i, --ignore-case 忽略大小写 -w, --word-regexp 强制 PATTERN 仅完全匹配字词 -x, --line-regexp 强制 PATTERN 仅完全匹配一行 -z, --null-data 一个 0 字节的数据行,但不是空行Miscellaneous(杂项): -s, --no-messages suppress error messages(预制错误信息) -v, --invert-match select non-matching lines(选择非匹配行) -V, --version display version information and exit --help display this help text and exit输出控制: -m, --max-count=NUM NUM 次匹配后停止 -b, --byte-offset 输出的同时打印字节偏移 -n, --line-number 输出的同时打印行号 --line-buffered 每行输出清空 -H, --with-filename 为每一匹配项打印文件名 -h, --no-filename 输出时不显示文件名前缀 --label=LABEL 将LABEL 作为标准输入文件名前缀 -o, --only-matching show only the part of a line matching PATTERN(模式) -q, --quiet, --silent suppress all normal output(抑制所有正常输出) --binary-files=TYPE assume(假设) that binary files are TYPE; TYPE is 'binary', 'text', or 'without-match' -a, --text equivalent to(等价于) --binary-files=text -I equivalent to(等价于) --binary-files=without-match -d, --directories=ACTION how to handle directories; ACTION is 'read', 'recurse(递归)', or 'skip' -D, --devices=ACTION how to handle devices, FIFOs and sockets; ACTION is 'read' or 'skip' -r, --recursive like --directories=recurse -R, --dereference-recursive likewise, but follow all symlinks --include=FILE_PATTERN search only files that match FILE_PATTERN --exclude=FILE_PATTERN skip files and directories matching FILE_PATTERN --exclude-from=FILE skip files matching any file pattern from FILE --exclude-dir=PATTERN directories that match PATTERN will be skipped. -L, --files-without-match print only names of FILEs containing no match -l, --files-with-matches print only names of FILEs containing matches -c, --count print only a count of matching lines per FILE -T, --initial-tab make tabs line up (if needed) -Z, --null print 0 byte after FILE name文件控制: -B, --before-context=NUM 打印以文本起始的NUM 行 -A, --after-context=NUM 打印以文本结尾的NUM 行 -C, --context=NUM 打印输出文本NUM 行 -NUM same as --context=NUM --group-separator=SEP use SEP as a group separator --no-group-separator use empty string as a group separator --color[=WHEN], --colour[=WHEN] use markers to highlight the matching strings; WHEN is 'always', 'never', or 'auto' -U, --binary do not strip CR characters at EOL (MSDOS/Windows) -u, --unix-byte-offsets report offsets as if CRs were not there (MSDOS/Windows)
以上内容均来自grep –help,本人仅作部分翻译及收集整理。更多详细内容可以参考:man grep。
3.使用示例 帮助内容看起来有点多,我们就挑选比较常用的来学习好了。 (1)常规用法 -a :将二进制文件以文本文件的方式查找数据,也就是不忽略二进制文件内的查找。[grep@GeekDevOps ~]$ file /bin/dir/bin/dir: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=cb457e6070d3129721df79b26c999b4d08ed1ea7, stripped[grep@GeekDevOps ~]$ grep "dir" /bin/dir匹配到二进制文件 /bin/dir[grep@GeekDevOps ~]$ grep "dir" /bin/dir -a #此处有输出异常
-c :计算找到 ‘搜寻字符串’ 的次数。
[grep@GeekDevOps ~]$ grep -c "root" /etc/passwd2
-i :忽略大小写的不同,所有大小写视为相同。
[grep@GeekDevOps ~]$ sudo grep -i "root" /etc/ssh/sshd_config #PermitRootLogin yes# the setting of "PermitRootLogin without-password".#ChrootDirectory none
-n :输出查找到内容的行号。
[grep@GeekDevOps ~]$ sudo grep -n "root" /etc/ssh/sshd_config119:#ChrootDirectory none
-v :反向选择,不包含搜索内容的全部内容都输出。
[grep@GeekDevOps ~]$ grep -v "s" /home/grep/.bashrc fi# export SYSTEMD_PAGER=
在以上操作中为了快速找到搜索内容,可以加–color=auto,我的屏幕上输出的内容是粉红色的,很显眼。
-w:搜索内容完全匹配字词。[grep@GeekDevOps ~]$ grep -w "SYS" /home/grep/.bashrc --color=auto[grep@GeekDevOps ~]$ grep -w "SYSTEMD_PAGER" /home/grep/.bashrc --color=auto# export SYSTEMD_PAGER=
-A :后面可加数字,为 after 的意思,除了列出该行外,后续的 n 行也列出来。
[grep@GeekDevOps ~]$ grep -n -A2 "root" /etc/passwd1:root:x:0:0:root:/root:/bin/bash2-bin:x:1:1:bin:/bin:/sbin/nologin3-daemon:x:2:2:daemon:/sbin:/sbin/nologin--10:operator:x:11:0:operator:/root:/sbin/nologin11-games:x:12:100:games:/usr/games:/sbin/nologin12-ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
-B :后面可加数字,为 befer 的意思,除了列出该行外,前面的 n 行也列出来。
[grep@GeekDevOps ~]$ grep -n -B1 "root" /etc/passwd1:root:x:0:0:root:/root:/bin/bash--9-mail:x:8:12:mail:/var/spool/mail:/sbin/nologin10:operator:x:11:0:operator:/root:/sbin/nologin
(2)高级用法
谈到grep的高级用法,难免就会联想到正则表达式!在之前的文章我就介绍过正则表达式,当时只是介绍并未举例。现在我们逐一来实践一下。 \:转义。[grep@GeekDevOps ~]$ grep -c "\n" /etc/passwd22
^:匹配字符串开始。
[grep@GeekDevOps ~]$ grep -n "^root" /etc/passwd1:root:x:0:0:root:/root:/bin/bash
$:以匹配字符串结尾。
[grep@GeekDevOps ~]$ grep -n "bash$" /etc/passwd1:root:x:0:0:root:/root:/bin/bash22:grep:x:1000:1000::/home/grep:/bin/bash
.:匹配除换行符之外的任意单个字符。
 这里必须用图片展示才能阐释清楚了,请看粉红色部分! []:匹配中括号内部的任意一字符。
这里必须用图片展示才能阐释清楚了,请看粉红色部分! []:匹配中括号内部的任意一字符。 [grep@GeekDevOps ~]$ grep -n "^[abcd]" /etc/passwd2:bin:x:1:1:bin:/bin:/sbin/nologin3:daemon:x:2:2:daemon:/sbin:/sbin/nologin4:adm:x:3:4:adm:/var/adm:/sbin/nologin14:avahi-autoipd:x:170:170:Avahi IPv4LL Stack:/var/lib/avahi-autoipd:/sbin/nologin17:dbus:x:81:81:System message bus:/:/sbin/nologin
[-]:配置中括号内指定范围的任意一字符。
[grep@GeekDevOps ~]$ grep -n "^[a-d]" /etc/passwd2:bin:x:1:1:bin:/bin:/sbin/nologin3:daemon:x:2:2:daemon:/sbin:/sbin/nologin4:adm:x:3:4:adm:/var/adm:/sbin/nologin14:avahi-autoipd:x:170:170:Avahi IPv4LL Stack:/var/lib/avahi-autoipd:/sbin/nologin17:dbus:x:81:81:System message bus:/:/sbin/nologin
?:匹配之前的项一次或0次(单独的?是不支持基本表达式的,注意区分以下2图)。
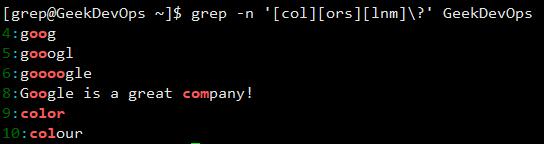
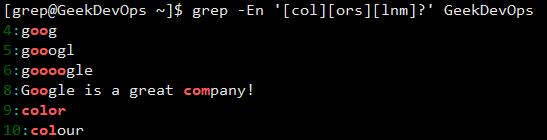 +:匹配之前的项一次或者多次。
+:匹配之前的项一次或者多次。  *:匹配0次或多次,比较常用。
*:匹配0次或多次,比较常用。 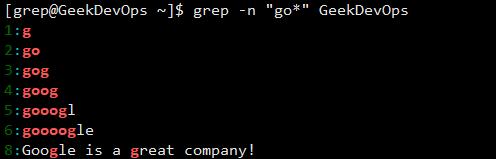 {}:匹配之前的项n次,n可以为0。
{}:匹配之前的项n次,n可以为0。  {m,}:匹配之前的项至少m次。
{m,}:匹配之前的项至少m次。  {m,n}:匹配之前的项至少m次,之多n次。
{m,n}:匹配之前的项至少m次,之多n次。 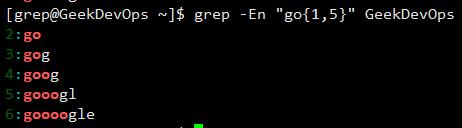 ():用于创建一个匹配的子串。 |:交替匹配|两边的任意一项。
():用于创建一个匹配的子串。 |:交替匹配|两边的任意一项。 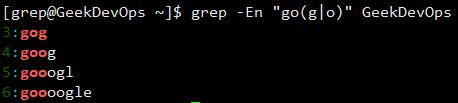 最常用的正则表达式至此基本介绍完毕。 在后面的sed及awk的使用中仍然会使用到正则表达式,在相关部分又继续介绍POSIX及元字符类的表达式。
最常用的正则表达式至此基本介绍完毕。 在后面的sed及awk的使用中仍然会使用到正则表达式,在相关部分又继续介绍POSIX及元字符类的表达式。
你可能感兴趣的文章
39.6. 硬盘情况
查看>>
[导入]Are Generics in .NET like Templates in C++?
查看>>
[转载]手机软件开发之我见
查看>>
UNITY实现FLASH中的setTimeout
查看>>
C#文件和文件文件夹按时间、名称排序-顺序与倒序
查看>>
表达式的计算结果必须为节点集。
查看>>
Python黑帽编程 3.5 DTP攻击
查看>>
再见乱码:5分钟读懂MySQL字符集设置
查看>>
多线程系列一
查看>>
[CareerCup] 1.5 Compress String 压缩字符串
查看>>
Windows 2008 R2 64位上安装wamp失败的原因
查看>>
法外之徒第一季/全集Braquo迅雷下载
查看>>
在阿里云环境下搭建基于SonarQube的自动化安全代码检测平台
查看>>
PHP实现四种基本排序算法 得多消化消化
查看>>
MongoDB概念解析
查看>>
Windows系统下IE单双多进程分析
查看>>
SmartNavigation在Fx2.0中下岗了...
查看>>
浅谈国内域名注册商与国外域名注册商的区别与优势
查看>>
嵌入式ROM和RAM的区别
查看>>
算法导论第十五章 动态规划
查看>>